Teaching your iSeries to surf the web: Consuming Web Services
So far we have discussed:
- using the iSeries and RPG as a web server that serves documents, such as our Sales Report
- using the iSeries and RPG to generate XML to the iSeries IFS or to a web client
- using RPG to parse XML found on the IFS or that came as a response from a web client or another web server.
Now the next topic is less intuitive. Why would I want to teach my iSeries to surf the internet? Don't I have enough employees that have mastered that skill already?
Here are a few reasons that you might want to do this
- to pick up foreign exchange rates to import into your international costing programs
- to retreive bank balances or bank statements data for automated cheque reconciliation
- to periodically retreive carrier shipping statuses (eg: UPS or Fedex)
This functionality requires a programming language that has vocabulary to initiate a request to remote computer, usually using the HTTP protocol. IBM makes this functionality available through a series of rather verbose APIs. Fortunately for us, Mr. Scott Klement took these APIs and built a set of procedures in a service program called HTTPAPI that simplifies this requirement. His procedures isolate us a bit from management of socket and memory pointers.
Below is an example (lifted shamelessly) from Mr Klement's collection of examples found in his download.
In this example
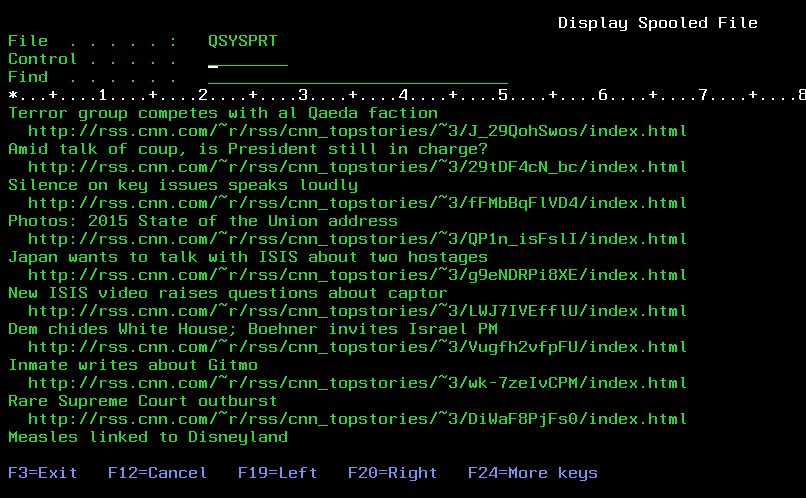
1) he uses procedure http_url_get() to get a stream of XML news stories from CNN.com
(Type http://rss.cnn.com/rss/cnn_topstories.rss in your browser to see what your RPG program will be reading!)
2) parses stream file using procedure http_parse_xml_stmf(). This is similar in functionality to RPG's built-in XML-INTO but has greater flexibility
3) print to printer file, the news headlines & links to the full articles
Here is full code.
H*
H* EXAMPLE11 - Example of parsing an XML document from the web with HTTPAPI and parsing with EXPAT
H* (Datchanee and everyone else - This example can be found in LIBHTTP library of download)
H*
H DFTACTGRP(*NO) BNDDIR('HTTPAPI')
FQSYSPRT O F 132 PRINTER OFLIND(*INOF)
/copy qrpglesrc,httpapi_h
/copy qrpglesrc,ifsio_h
D Incoming PR
D userdata * value
D depth 10I 0 value
D name 1024A varying const
D path 24576A varying const
D value 65535A varying const
D Attrs * dim(32767)
D const options(*varsize)
D num s 10I 0
D item ds occurs(10)
D title 512A varying
D artlink 512A varying
D msg s 50A
D rc s 10I 0
D url s 100A varying
D PrintLine s 132A
D x s 10I 0
D filename s 45A varying
/free
*inlr = *on;
http_debug(*ON);
// ****************************************************
// Download the latest news headlines from CNN
// to a temporary file in the IFS
// ****************************************************
url = 'http://rss.cnn.com/rss/cnn_topstories.rss';
filename = http_tempfile() + '.xml';
rc = http_url_get( url : filename );
if (rc <> 1);
PrintLine = http_error();
except;
unlink(filename);
return;
endif;
// ****************************************************
// parse the XML from the temp file.
// ****************************************************
if (http_parse_xml_stmf( filename
: HTTP_XML_CALC
: *null
: %paddr(Incoming)
: *null ) < 0 );
PrintLine = http_error();
except;
unlink(filename);
return;
endif;
// ****************************************************
// Print the news headlines & links to the full
// articles
//
// Note: If you wanted to, you could retrieve the
// articles themselves by calling http_url_get
// for each link.
// ****************************************************
if num > %elem(item);
num = %elem(item);
endif;
for x = 1 to num;
%occur(item) = x;
PrintLine = title;
except;
PrintLine = ' ' + artlink;
except;
PrintLine = '';
except;
endfor;
unlink(filename);
return;
/end-free
OQSYSPRT E
O PrintLine 132
*+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
* This is called for each XML element that's received in the
* document. The document that's received will look something
* like the following:
*
* <rss version="2.0">
* <channel>
* <title>Title of Newsfeed channel</title>
* <link>http://www.blahblahblah.com</link>
* <description>Whatever Headlines</description>
* <language>en-US</language>
* <item>
* <title>Title of first article</title>
* <link>link to first article</link>
* </item>
* <item>
* <title>Title of second article</title>
* <link>link to second article</link>
* </item>
* </channel>
* </rss>
*
* The DEPTH parameter indicates the nesting depth of the
* element received. In the above example, the "item" tag
* would be found at depth=3, since it's inside the "rss"
* and "channel" tags.
*
* The NAME parameter is the name of the XML element that
* has been received. It might be something like "channel"
* or "title" or "link".
*
* Note that in the above example, there are two different
* depths that have "title" and "link". They are featured
* inside the "channel" tag, and also inside the "item" tag.
* the "path" parameter will help us sort that out.
*
* The PATH indicates the elements that the current element
* is found inside. So, the channel title is found when the
* path is "/rss/channel" and the name of the element is "title".
* the article titles, however, have a path of "/rss/channel/item"
* and a name of "title".
*
* The VALUE parameter gives us the text that's inside that
* element.
*+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
P Incoming B
D Incoming PI
D userdata * value
D depth 10I 0 value
D name 1024A varying const
D path 24576A varying const
D value 65535A varying const
D attrs * dim(32767)
D const options(*varsize)
D count s 10I 0
D attrname s 1024A varying
D attrval s 65535A varying
/free
if (num > %elem(item));
return;
endif;
if ( path = '/rss/channel/item' );
select;
when name = 'title';
num = num + 1;
if (num <= %elem(item));
%occur(item) = num;
title = value;
endif;
when name = 'link';
artlink = value;
endsl;
endif;
// sometimes an element will have attributes. In the example
// XML shown above, the only attribute is the VERSION attrib
// of the RSS tag.
//
// The following searches through the attribute list of the
// rss tag to extract the version number.
if (name = 'rss');
count = 1;
dow http_nextXmlAttr(attrs: count: attrname: attrval);
if (attrname = 'version');
PrintLine = 'RSS version ' + attrval;
except;
endif;
enddo;
endif;
/end-free
P E
more on Scott Klement's LIBHTTP API.
input and output